Антон Семенюта
Антон Семенюта Query-Based Фьюз
Его ключевая идея в том, чтобы не проецировать признаки камер и лидара на общую сетку, а получать у них информацию с помощью cross-attention.
Классический представитель этого подхода — TransFusion.
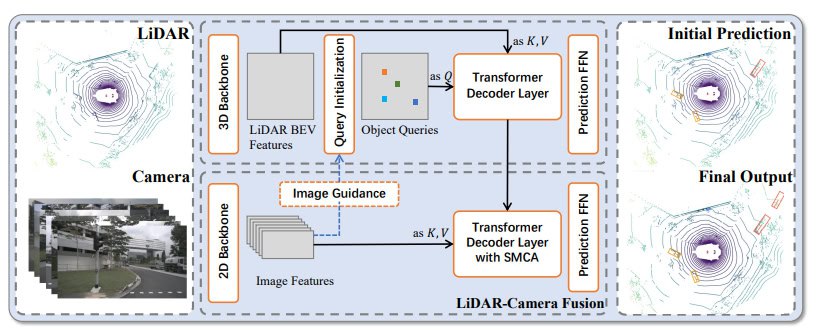
Архитектура похожа на обычный DETR
Модель использует набор обучаемых Object Queries — заготовок будущих объектов, которые содержат информацию об их потенциальном положении и признаках.
Процесс здесь двухстадийный:
- Сначала эти запросы через механизм внимания взаимодействуют с лидарными признаками. Лидар дает точную геометрию, поэтому на этом этапе модель примерно определяет, где находятся объекты.
- Затем обогащенные запросы через еще один слой кросс-внимания «обращаются» к признакам с камер. Это позволяет «подсмотреть» семантическую информацию — что это за объект (пешеход, машина, знак), уточнить его форму и другие визуальные детали.
На мой взгляд такой подход перспективнее предыдущего.
- BEV-подход упирается в производительность — нельзя бесконечно увеличивать размер BEVкарты, чтобы охватить очень дальние объекты, так как затраты памяти растут квадратично.
- Query-Based подход лишен этой проблемы. Количество запросов фиксировано и не зависит от размера сцены. Это делает его особенно перспективным для детекции на больших дистанциях, где важна камерная информация.
- С другой стороны BEVFusion проще дебажить. Мы можем визуализировать BEV-карту и буквально увидеть, куда спроецировались фичи с камеры или лидара.
Query-Based Фьюз