Ильдар Идрисов
Ильдар Идрисов Вводная в мое текущее исследование
Wake up, Neo… утро начнется со статьей.
Обычно обучение останавливают на плато или минимуме loss, и дополнительный сигнал - переобучение: train loss падает, а val loss растёт. Под это заточены early stopping, patience и выбор лучшего чекпоинта по валидации. Если loss больше не улучшается - можно заканчивать.
Проблема в том, что именно рядом с этой "точкой остановки" в модели нередко идут изменения, которые почти не видны по loss и accuracy, но заметно перестраивают внутреннюю структуру решения. Давайте разберем несколько таких вариантов.
1. Loss стабилен, но параметры и представления продолжают эволюционировать
Loss - это агрегированная величина: плато означает лишь, что средняя ошибка по выборке почти не меняется, а не то, что обучение остановилось. На практике после выхода loss на плато часто наблюдается сжатие представлений внутри классов, рост расстояний между классами и повышение устойчивости границ решений.
Это поведение теоретически описано здесь: в статье показано, что при линейно разделимых данных градиентный спуск продолжает движение даже после достижения нулевой ошибки, все больше разделяя классы.
Для более общих моделей этот эффект развивается в работе: поздняя стадия выглядит как движение вдоль "плоских" минимумов, где ошибка уже минимальна, но геометрия решения продолжает улучшаться.
2. 100% accuracy - не стоп сигнал
100% accuracy часто воспринимается как "модель выучилась", но это грубая бинарная метрика, она не видит, как именно устроены выходы модели. После достижения 100% точности обучение может продолжаться в "качественных" параметрах: модель наращивает уверенность, увеличивает зазор между классами и становится устойчивее к шуму. Эта логика разбирается в статье: авторы описывают фазы обучения, включая режим, где ошибка уже нулевая, но параметры продолжают систематически меняться. Похожие выводы о поздней "достройке" геометрии решения есть в работе.
3. Сначала запоминание, потом структура
Интуитивно кажется, что модель сначала учит "общие закономерности", а потом начинает заучивать и переобучаться. На практике нередко наоборот: модель быстро подгоняется под обучающую выборку (низкий loss), затем долго почти не меняется, а при дальнейшем обучении перестраивает представления и переходит в другой, более "структурный" минимум.
Это показано в статье: сети рано подхватывают простые и шумные шаблоны, а более абстрактные зависимости формируются позже. Крайний случай - grokking: модель длительный период плохо обобщает, а затем резко переходит к почти идеальному решению. В этих экспериментах модель долго находится в минимуме, связанном с запоминанием, а затем выходит во второй, структурный минимум.
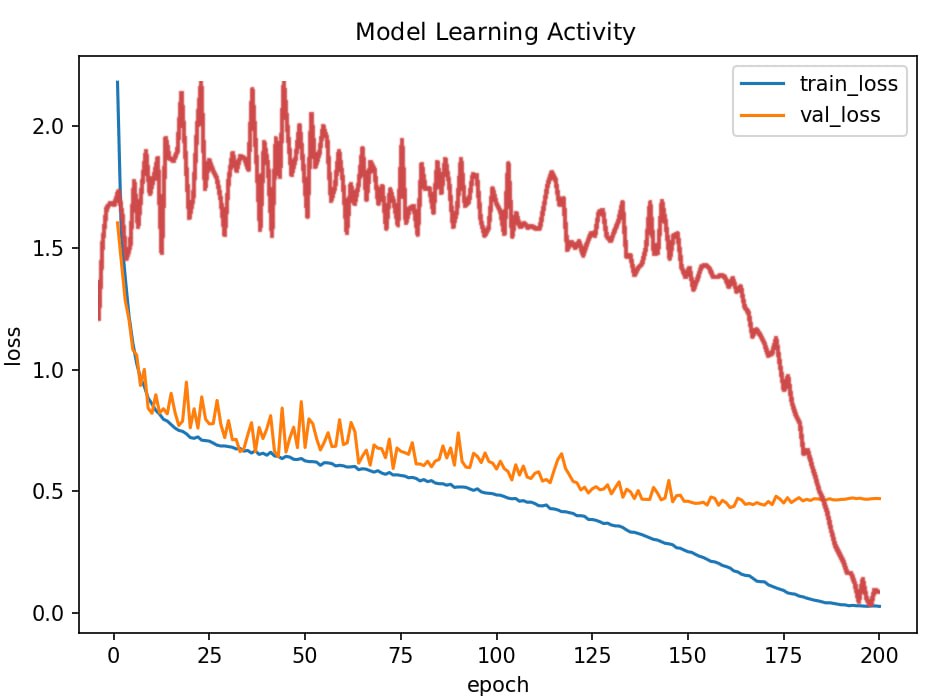
4. Рост validation loss не всегда деградация
Классическое "переобучение" - train loss падает, а val loss растет - часто трактуют как однозначный сигнал остановки. Но в реальных моделях это может быть переходная фаза, связанная с перестройкой представлений, а не с окончательной деградацией.
Это согласуется с эффектом double descent, показанный в работе: качество может временно ухудшаться, а затем снова улучшаться при дальнейшем обучении. Рост val loss может сопровождать перестройку представлений, а не их деградацию.
5. Поздняя стадия обучения - это отдельный режим, а не “шум”
Поздний этап часто называют шумом вокруг минимума, но у SGD есть собственная динамика, зависящая от lr, размера батча и стохастичности. В работах раз и два поздняя стадия трактуется как неравновесное состояние, а не как бессмысленный хвост оптимизации.
Вывод
Привычные стоп-сигналы: loss plateau, overfitting и 100% accuracy - часто означают не конец обучения, а начало тонкой перестройки модели. Early stopping ускоряет эксперименты и упрощает отбор, но нередко фиксирует модель в первом поверхностном минимуме. А именно рядом с точкой, где мы обычно останавливаемся, в модели происходят очень интересные эффекты. И если смотреть только на loss и accuracy, этот момент почти всегда остаётся незаметным
Вводная в мое текущее исследование