Ильдар Идрисов
Ильдар Идрисов Незавершенное исследование
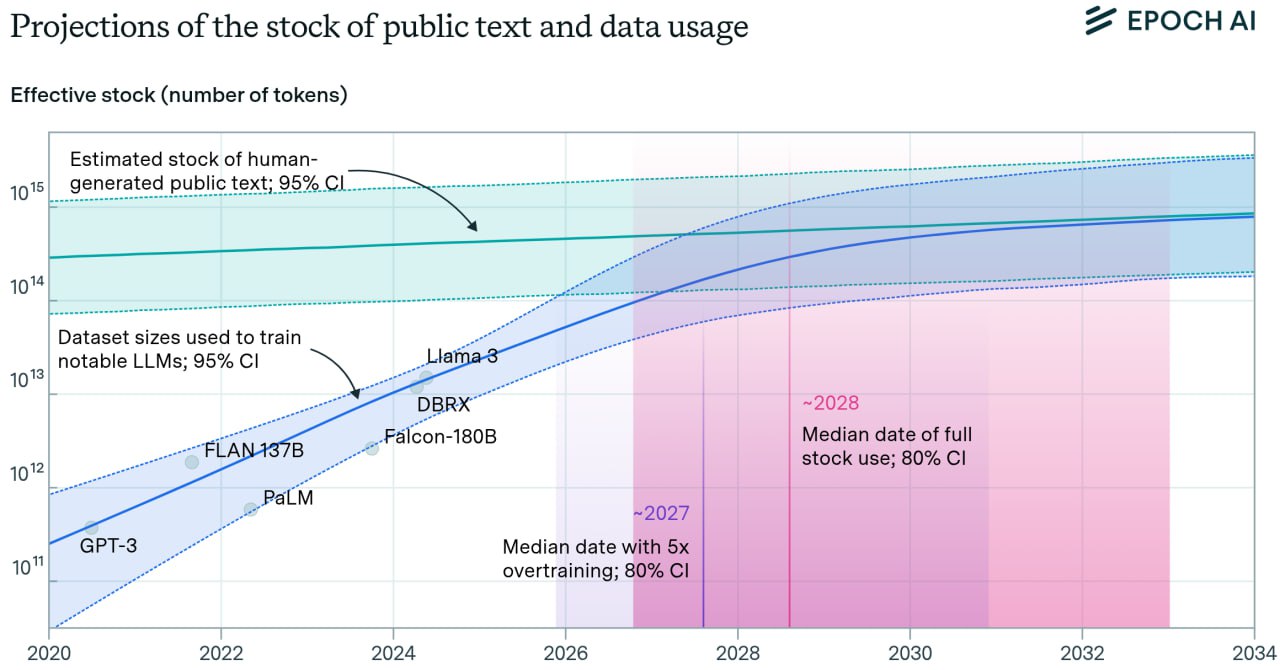
Думаю, все уже много раз слышали, что мы спылесосили весь интернет. LLM неоткуда брать новые знания. Они учатся на нейрослопе от других LLM-ок. Теория мертвого интернета через несколько лет может стать действительностью. По разным оценкам проблемы начнутся уже в следующем году. А делать то что? Откуда нам брать новые знания?
1. Комбинирование уже существующих знаний
При помощи LLM-ок можно генерировать “новое” знание при помощи понятных импликаций и аксиом вывода: мы знали, что A верно. И знали, что A --> B. Значит, мы открыли новое знание “B верно”. Звучит несложно, но если доказательство “А верно” лежит в забытой статье по теоретической физике прошлого века, а “А-->B” в статье по молекулярной биологии, то человеку “откопать” эти связи практически очень сложно, а LLM-ке проще. Так можно получать новые знания при помощи комбинирования существующих.
2. Открытие нового знания
Тут интереснее. Допустим, мы поняли структуру мира, разложили все по полочкам и увидели пробелы, их мы довольно быстро заполним. Как это было с таблицей Менделеева. Получается на этом все? Нет. В науке есть много примеров открытий, которые выбиваются из этого шаблона. Некоторые открытия были сделаны (барабанная дробь) - случайно. Т.е. Выходя за границу изученного мы можем случайно найти некую новую закономерность, которую позже объясним, подвяжем к нашей текущей структуре и дальше по пункту 1 заполним пробелы. Как бы нелепо это не звучало, но в создании нового знания случайность играет довольно важную роль. Как иначе открыть то, чего мы не знаем? Как найти нечто в темном чулане? Нужно в него зайти, споткнуться об это нечто и потом попытаться объяснить. Отсюда и началось мое исследование.
Это было одним из первых моих самостоятельных изысканий. Я здесь прошел через разные техники, например ТРИЗ Альтшуллера и теорию информации. И пришел к выводам, что для получения новых знаний с применением случайности нужно их переложить в абстрактное компактное пространство. Это привело например к гипотезе, что LLM-ки нужно кормить токенами не в виде частей слов, а логическими блоками. После чего их можно представлять в виде понятного для человека текста, но только по необходимости. Наша мета LLM будет выполнять роль обработчика причем с очень высокой скоростью, и только результат будет выложен в виде текста. Можно делать несколько таких надстроек на разном уровне логических представлений. Дальше имея такую пирамиду можно подмешивать в верхние уровни случайность, а нижние будут систематизировать их. И если нам добавить обратную связь с нижних уровней до верхних, проверяя верность полученных утверждений и управляя случайностью, то многократные итерации могу в какой-то момент привести к получению чего-то нового. А это уже может быть не просто комбинация текущих знаний, а получение новых
Незавершенное исследование